
撰稿 | AiBrain 内容团队
排版 | AiBrain 编辑团队

近年来,基于脑电图(EEG)的情绪识别越来越受到关注。与记录面部表情、身体姿势、声音等的行为技术不同,EEG提供了对人类情绪反应的更直接和客观的测量,这种测量不能轻易伪装或有意识地抑制。与功能磁成像(fMRI)和脑磁图(MEG)等其他神经成像技术相比,EEG在现实应用中具有便携性和成本效益优势。
广泛的研究已经了解了情绪相关的EEG表征,包括微分熵(DE)特征、卷积神经网络(CNN)和注意力机制等方法被用于以端到端的方式学习情绪相关的EEG表征,这些方法利用了深度神经网络的显著代表能力,避免了人为的特征提取,然而,大多数研究主要集中于主体内情绪识别。因此,开发具有良好跨学科通用性的情感识别方法对于现实应用是可取的,尤其是在新用户的情况下。
2022年4月4日,清华-IDG/麦戈文脑科学研究院的宋森课题组和清华大学心理学系张丹课题组在IEEE TRANSACTIONS ON JOURNAL NAME上发表了题为“Ensembles of endothelial and mural cells promote angiogenesis in prenatal human brain”的研究文章,该研究开发了基于对比学习的群体共性神经表征提取方法(Contrastive Learning of Inter-Subject Alignment, CLISA),该方法在跨个体情绪状态识别的应用中取得了较好的效果。


首先,作者介绍了对比学习方法(CLISA)(图1),包括对比学习的过程和解释CLISA的预测过程。在对比学习过程中,作者利用一个带有卷积层的基础编码器和投影来对齐不同个体的数据表示。在预测过程中,作者使用学习表征来识别脑电信号的情绪标签。
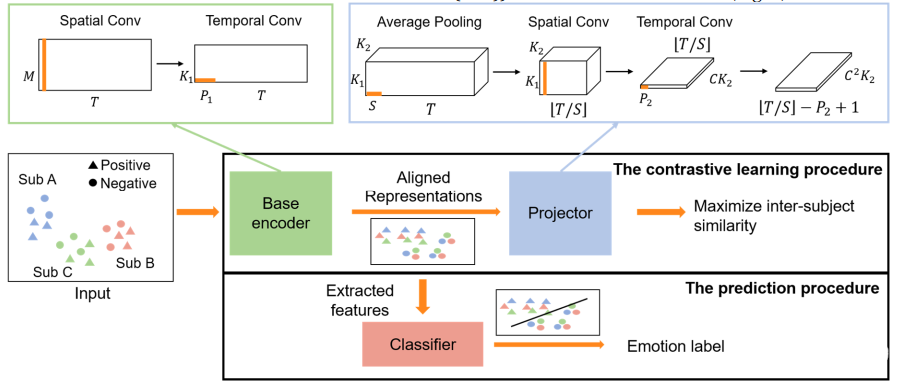
图1:学科间比对学习方法(CLISA)的说明。
本研究模型在区分THU-EP数据集上的积极和消极情绪状态方面实现了71.9±8.8%的二元分类准确率(表1)。与直接提取DE特征的对照模型(即DE+MLP)相比,CLISA显著提高了6.7%。这一比较表明,通过对比学习方法学习的表征比简单的DE特征在跨主题情绪识别方面更强大。
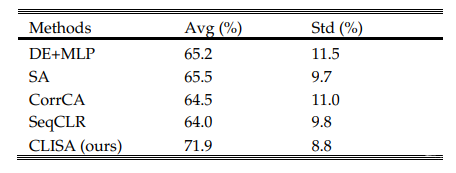
表1:不同方法对THU-EP数据集的二分类准确率
CLISA也显著优于其他受试者间比对方法,包括SA、CorrCA和SeqCLR。ROC曲线下的面积进一步说明了所提出方法的有效性,因为它在所有阈值下的预测能力明显优于其他竞争基线(图2)。
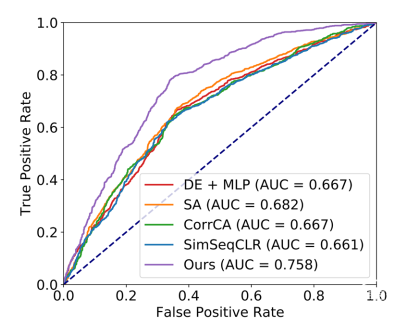
图2:绘制THU-EP数据集二分类的受试者工作特征(ROC)曲线。
为了说明对比学习的效果,作者通过t-sne嵌入可视化了五个示例对象的原始特征和预训练的特征(图3)。从EEG信号中提取的原始DE特征分别分散在不同受试者的t-sne嵌入空间中(图3a)。相比之下,CLISA产生的训练DE特征被合并在一起,不同的情感类别仍然是可分离的(图3b),表明模型可以有效地缓解主体差异,而不损失情感可分性,从而促进跨主体情感识别。
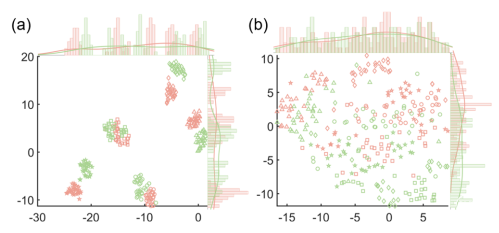
图3:(a)原始微分熵(DE)特征的t-sne结果。(b)从训练后的基编码器输出中提取DE特征的t-sne结果。
CLISA方法的性能大大得益于对比学习中训练对象数量的增加(图4)。为了研究训练对象数量的影响,作者在对比学习过程中随机选择了具有不同主题数量(8、16、24、32、40、48、56、64或72)的训练对象子集。结果显示,CLISA在不同数量的训练对象下,CLISA的表现随着训练对象数量的增加而显著提高。
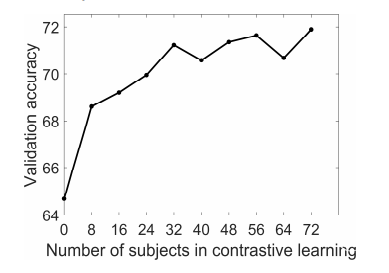
图4:对比学习的验证准确率随着训练对象的数量而增加。
在关于测试对象的新刺激的通用性测试中,本模型实现了63.4±17.1%的分类准确率(表2),高于所有基线模型。这一结果表明,该模型过度拟合或记忆了它在对比学习中已经看到的刺激(即视频)。

表2:对THU-EP数据集的概化性检验
在九级情感分类任务中,CLISA显著超过所有其他竞争方法,提高了10.2%(表4)。CLISA在这些任务上与SA、CorrCA和SeqCLR相比的持续改进表明,本研究的方法优于其他线性变换方法或其他对比学习策略。
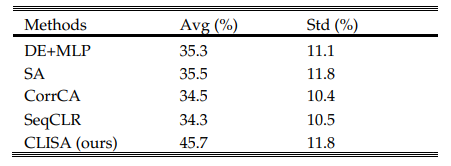
表3:不同方法在THU-EP数据集上的9类分类准确率
基于CLISA的预测结果,作者进一步分析了不同情绪类别的混淆矩阵(图5)。结果显示,厌恶情绪可以高精度地识别,表明其清晰的神经表征和高的主体间一致性。在积极的情绪中,娱乐和温柔是最好的。
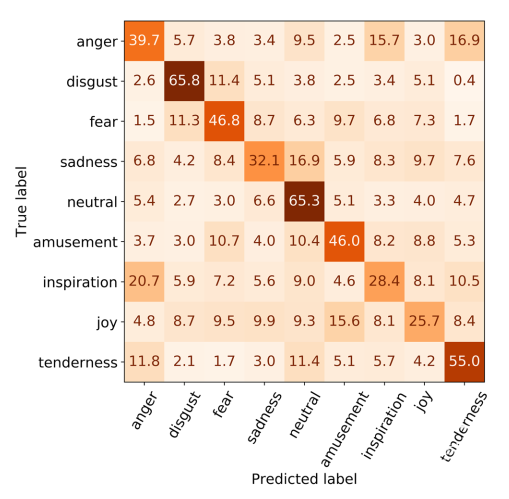
图5:THU-EP数据集的九类情绪分类混淆矩阵。
本研究的方法的有效性也在广泛使用的SEED数据集上进行了评估。CLISA在三级情绪分类任务中获得了86.4±6.4%的准确率(表4)。与THU-EP数据集类似,CLISA的预测性能优于DE+MLP、SA、CorrCA和SeqCLR。
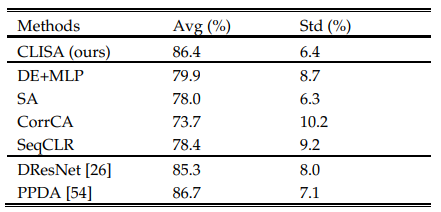
表4:不同方法对SEED数据集的分类精度
此外,CLISA的性能与先前研究中报告的最新模型(DResNet和PPDA)的性能相当。与领域对抗策略相比,它进一步证明了本研究的对比学习策略的有效性。本研究的模型的混淆矩阵如图6所示。该模型倾向于将负面情绪与其他两种情绪混淆,尤其是中性情绪,积极情绪的分类更准确。

图6:SEED数据集的混淆矩阵。
在SEED数据集的可推广性测试中,本研究的模型实现了最高的分类准确率,为77.4±13.4%(表5),尽管改进没有统计学意义。这一结果进一步验证了本模型对从未见过的新刺激(即视频)的通用性。
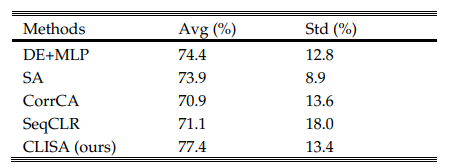
表5:种子数据集的概化性测试
最后作者介绍了CLISA提取的主题间对齐的时空表示。作者分析了每个情绪类别的两个最重要的特征和最大的重要指数。
在SEED数据集上,本研究识别了主要在前颞区的负面情绪的空间激活,频率响应在12-21 Hz和4 Hz左右(图7)。对于积极情绪,空间激活集中在时间区域,频率响应高于25Hz。中性状态在4-8Hz左右具有额叶和颞叶激活,在超过25Hz的高频下具有左颞叶激活。
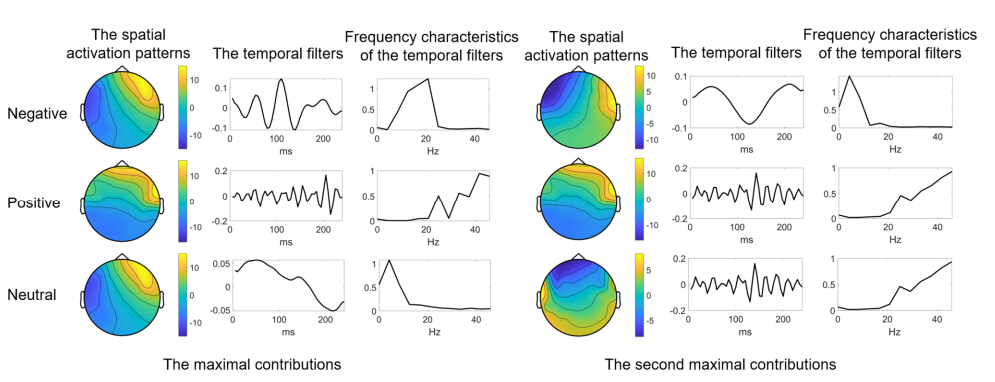
图7:对SEED数据集进行情绪分类的重要特征的时空特征分析。我们分别将负性、正性和中性情绪的空间激活模式、时间滤波器和时间滤波器的频率特性可视化。
综上所述,CLISA方法从提取群体共性神经表征的角度出发,运用对比学习的策略实现个体间脑电表征的“功能对齐”,并在情绪状态识别的应用任务上取得了良好的表现。
CLISA将脑电时间序列作为输入,用空域卷积和时域卷积对脑电信号进行个体间功能对齐。
相比于此前大多数文献直接用提取好的特征作为模型输入的做法,CLISA的设计使模型具有更好的可解释性。获取空域激活模式使得进一步做信号源定位成为可能。
参考文献:
X. Shen, X. Liu, X. Hu, D. Zhang and S. Song, "Contrastive Learning of Subject-Invariant EEG Representations for Cross-Subject Emotion Recognition," in IEEE Transactions on Affective Computing, doi: 10.1109/TAFFC.2022.3164516.
AiBrain内容团队为大家整理了文章的pdf,如有需要,请公众号后台留言“pdf”或扫码添加AiBrain助手微信获取。



声明:脑医汇旗下神外资讯、神介资讯、脑医咨询、AiBrain所发表内容之知识产权为脑医汇及主办方、原作者等相关权利人所有。未经许可,禁止进行转载、摘编、复制、裁切、录制等。经许可授权使用,亦须注明来源。欢迎转发、分享。